
What PCA Actually Does in the Real World

I was reading about face recognition algorithms a few weeks ago and kept running into a statistics method called Principal Component Analysis. It showed up in a paper about children with a rare adrenal condition, and then again in a completely separate paper about predicting Alzheimer’s disease. Same math, totally different applications. That’s what made me want to actually dig into it.
So here’s what I found.
It Starts With Faces
One of the earliest and most famous uses of PCA is something called Eigenfaces. In 1991, researchers at MIT figured out that if you run PCA on a database of face images, the principal components that come out literally look like faces - ghostly, blurred versions of faces that each capture a different source of variation across the dataset. To recognize a new face, you just project it onto those components and get a compact set of scores. Compare those scores to your database and you have face recognition. Turk and Pentland reported 96% accuracy in 1991, on a standard workstation, powered entirely by PCA.
That’s the core idea: take thousands of variables (in this case, pixels) and compress them into a small number of components that still capture what matters. That same logic is exactly what researchers are now applying to medicine.
What Is PCA Exactly?
Before getting into the medical papers, it helps to be precise about what PCA actually does.
PCA stands for Principal Component Analysis. It takes a dataset with many variables and produces a smaller set of new variables called principal components. Each principal component is a weighted combination of the original variables, where the weights are determined by what captures the most variance in the data. The first component explains the most variance, the second explains the next most, and they are all uncorrelated with each other.
For PCA to work properly, the variables need to be linearly related to each other, the data needs to be standardized so everything is on the same scale, and it works best when variables can be negative. There are also specialized versions - Kernel PCA handles nonlinear relationships, Robust PCA deals with outliers, and there are others like Independent Component Analysis and Probabilistic PCA. But standard PCA is what both studies below used, and it was enough.
The key insight is that PCA does not create new information. It reorganizes existing information more efficiently. In face recognition, that means compressing 10,000 pixel values into maybe 50 Eigenface scores without losing the ability to tell people apart. In medicine, it means compressing a panel of hormone measurements or brain scan pixels into a single score that a doctor can actually use.
Study 1: Predicting Alzheimer’s Disease From a Brain Scan
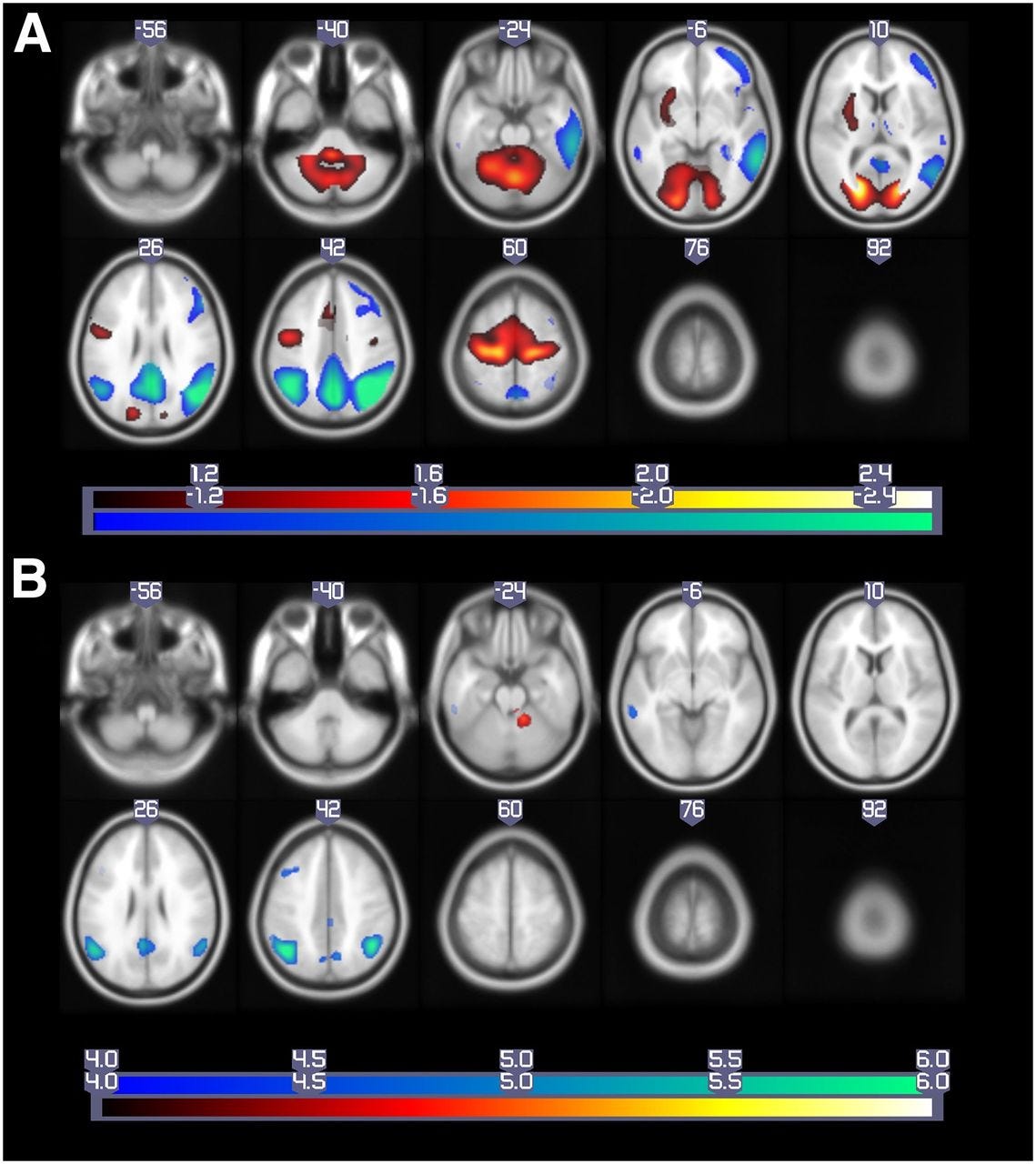
One of the more interesting papers I read was published in the Journal of Nuclear Medicine in 2019 by Blazhenets et al. The question: can you look at a brain scan today and predict whether someone will develop Alzheimer’s dementia years from now?
The tool they used was called 18F-FDG PET scanning. PET stands for positron emission tomography. It measures glucose metabolism in the brain because wherever glucose goes, brain activity follows. So a PET scan is a map of how active different brain regions are at a given moment.
The problem is that one of these scans produces thousands of data points. Each pixel in the image represents metabolic activity at a specific location. Sound familiar? Just like with face images, you cannot stare at thousands of pixels and make a good clinical decision. You need PCA to compress them into something usable
.
What They Did
They took 18F-FDG PET scans from patients with mild cognitive impairment (an early warning sign before Alzheimer’s) and tracked them over time to see who eventually converted to full Alzheimer’s dementia and who didn’t. Before running PCA, they normalized the images by fitting each brain scan to a standard template and smoothing the data for consistency. They also ran a preprocessing step to remove uninformative global and regional averages.
Then came the PCA itself. They selected principal components capturing the top 50% of variation in the data, then used linear regression to find which of those components differentiated converters from non-converters.
From the PCA, they extracted a single number called the Pattern Expression Score, or PES. It captures the overall metabolic signature of the brain. Think of it like an Eigenface score, except instead of “how much does this face look like component 3,” it’s “how much does this brain’s metabolism match the Alzheimer’s pattern.”
They also built a separate comparison model called a Volume of Interest (VOI) model, which used t-tests to identify individual brain pixels that differed between groups. Then they combined PES, the VOI predictions, and clinical variables into a Cox regression model to predict conversion over time.
What They Found
The combined model performed best overall. But the key finding was that the PES from PCA outperformed the VOI model alone. The holistic PCA-generated score was more predictive than monitoring individual brain regions in isolation.
They also confirmed that the PCA pattern matched regions already known to be affected in Alzheimer’s, like the posterior cingulate and parietal cortex. The math was picking up on biologically real signals, not noise.
If a PET scan processed through PCA can predict years in advance who will develop Alzheimer’s, that means earlier diagnosis and earlier treatment. PCA turned thousands of pixels into one meaningful, predictive number.
Study 2: Using PCA to Monitor Treatment in Kids With a Rare Hormone Disorder
This is the paper I found second, but its the more detailed of the two. It was published in Frontiers in Endocrinology in 2021 by Ljubicic et al., and it’s about children with Congenital Adrenal Hyperplasia, or CAH.
What Is CAH?
CAH is a genetic disorder. The most common cause is a deficiency in an enzyme called 21-hydroxylase, which is part of the process your adrenal glands use to make hormones. When it doesn’t work properly, the whole system goes out of balance.
Cortisol and aldosterone are underproduced. At the same time, 17-hydroxyprogesterone (17-OHP) and androgens build up because the blocked pathway redirects hormones elsewhere. In children, this causes real problems such as abnormal growth, BMI changes, early puberty, virilization, and blood pressure issues.
There are two main forms: classical CAH, which is more severe, and non-classical CAH, which has more residual enzyme activity and milder symptoms.
Treating CAH in kids is genuinely difficult. Doctors have to balance glucocorticoid doses carefully: too little and the disease isn’t controlled, too much and you risk stunting growth or triggering other side effects. Every clinic visit involves measuring a growing panel of hormones and making a judgment call. As the paper states, “interpreting combinations of these markers introduces complexity, subjectivity, and bias into the patient care.” That’s the same problem face recognition had before Eigenfaces. There are too many variables and no good way to combine them. PCA is the solution in both cases.
The Data
The study followed 33 children and adolescents, ranging in age from just under one year old to nearly nineteen, at a clinic in Copenhagen. Over time, those 33 patients racked up 406 total clinic visits. The researchers treated each visit as its own data point, since treatment is adjusted visit by visit in the real world anyway.
At every visit, seven hormones were measured from a blood sample. Four of them are adrenal steroids directly tied to CAH - 17-OHP, DHEAS, androstenedione, and testosterone. The other three - SHBG, LH, and FSH - give a broader picture of how the endocrine system is functioning overall.
Here’s one thing the study did really cleverly: instead of using the raw hormone numbers, they converted everything into standard deviation scores adjusted for age and sex. So instead of asking “is this testosterone level high?”, they asked “is this testosterone level high for a 7-year-old girl?” That adjustment meant a toddler and a teenager could sit in the same PCA model without the age difference distorting everything. It’s the kind of detail that sounds small but actually makes or breaks whether the analysis is valid.
What PCA Found
Because classical and non-classical CAH are biologically different diseases, the researchers ran PCA separately for each group rather than lumping everyone together.
The results were already interesting before they even got to the treatment question. In classical CAH, the first principal component, the one capturing the most variation across all patients, was almost entirely explained by one hormone: 17-OHP. It had a correlation of 0.93 out of 1.0 with that component, meaning 17-OHP was basically driving the whole first dimension of variation on its own. In non-classical CAH, the picture was messier. The first component was shared more evenly across multiple hormones, with 17-OHP, DHEAS, androstenedione, and testosterone all contributing meaningfully.
What that tells you is that the two forms of CAH don’t just differ in severity, they differ in their underlying hormonal structure. Classical CAH is dominated by the hormone 17-OHP. Non-classical CAH is more complicated. PCA made that visible in a way that a table of average hormone values couldn’t.
Did the PC Scores Actually Predict Treatment?
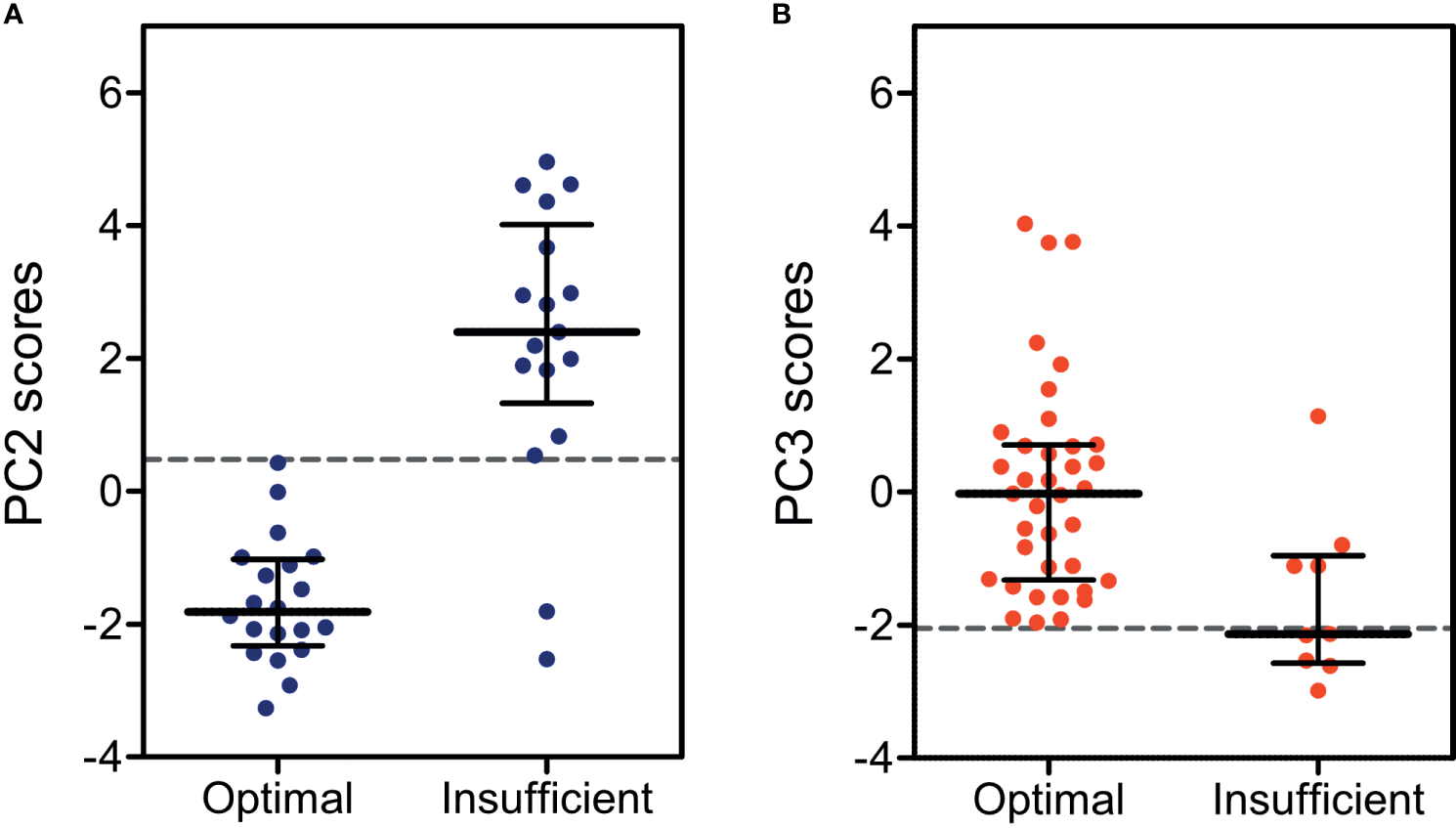
This is the key question. The researchers assessed treatment efficacy using clinical markers - things like how close a child’s height was to their expected height, their BMI, and their blood pressure. Crucially, none of these clinical markers went into the PCA model. The PCA only saw hormone data. So the test was: can a score built purely from hormones predict whether a child is being treated well or not?
To measure predictive accuracy, they used something called an AUC score - area under the ROC curve. You can think of it as a grade for how good a predictor is. A score of 50% means you might as well flip a coin. A score above 90% is considered excellent.
The individual hormones did not do well. 17-OHP, which is the hormone doctors most commonly rely on for CAH management, scored an AUC of just 56%. Barely above random. The best single hormone was FSH, which reached 80% accuracy, but still missed a lot of cases.
The PCA scores were a different story. For classical CAH, the second principal component score hit an AUC of 93% and an overall accuracy of 95%. For non-classical CAH, the third principal component reached 80% AUC and 91% accuracy. The classical model caught every single insufficiently treated patient - 100% sensitivity. None slipped through.
That 17-OHP result is the one I keep coming back to. It’s the hormone CAH patients get monitored on most closely, and it basically told doctors nothing about whether treatment was working. That’s not a knock on the doctors - the clinical guidelines actually acknowledge this already. But it does show why combining multiple hormones through something like PCA matters is so meaningful
.
A Side Finding Worth Mentioning
At the end, the researchers ran one more PCA combining all patients together - both classical and non-classical - just to see what would happen. When they plotted the results, the two groups naturally separated into distinct clusters without any instruction to do so. The math just sorted them.
Looking at which hormones drove that separation, they noticed that 17-OHP and DHEAS were pointing in completely different directions in the plot. That suggested their ratio might be useful for telling the two forms of CAH apart. They tested it and found an accuracy between 81 and 89%. It’s not ready for clinical use yet since most patients were already on treatment during the study, which changes hormone levels. But it’s a new lead that PCA generated just by finding structure in the data
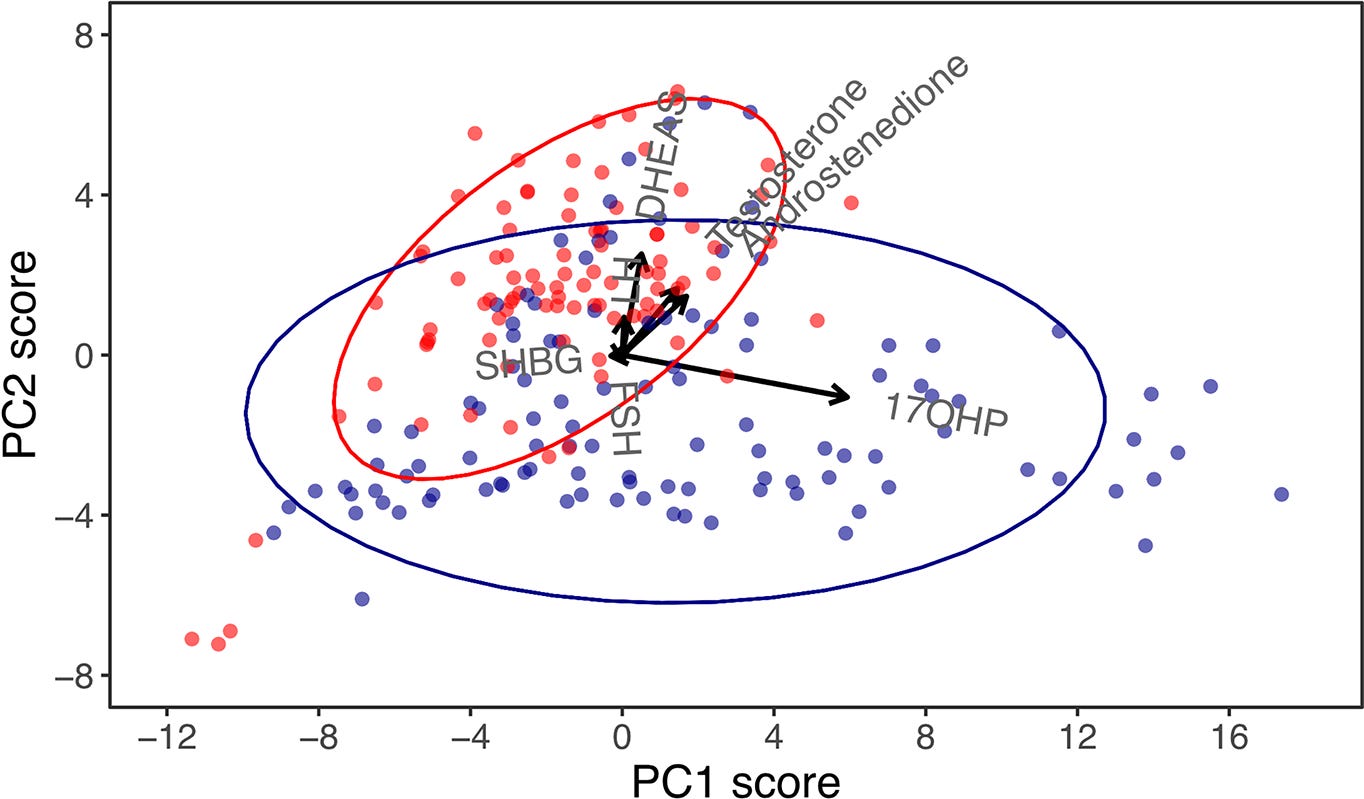
.
What All Three Have in Common
It’s kind of interesting that the same statistical method shows up in face recognition, Alzheimer’s research, and pediatric endocrinology. On the surface those things have nothing to do with each other. But the underlying problem is the same every time - there’s too much data, too many variables, and you need a way to make sense of it without just staring at a spreadsheet.
PCA solves that by finding the structure that’s already in the data and expressing it more cleanly. Whether that’s pixels in a face image or hormone levels in a 6-year-old, the math works the same way.
That said, both medical studies are early-stage work. The CAH study had only 33 patients, and the authors themselves describe it as a pilot study. The Alzheimer’s study had 272 patients, which is bigger, but still a relatively small sample for the kind of model they were building. Neither is ready to change clinical practice on its own. They both need to be tested on larger, more diverse populations first.
What I Actually Think
Medicine tends to look at one thing at a time. One hormone, one brain region, one marker. But the body doesn’t really work that way - everything is connected, and looking at variables in isolation misses a lot. What PCA does is take that interconnectedness seriously and actually do something useful with it.
I also think it’s just genuinely cool that the same method works across such different problems. The researchers studying CAH in kids and the ones analyzing brain scans weren’t thinking about face recognition, but they were all reaching for the same tool for the same reason. That kind of cross-domain consistency usually means something is onto something real.
Both papers are careful to acknowledge their limitations, and a 33-patient pilot study obviously isn’t enough to change how doctors practice medicine. But as a proof of concept, both are pretty convincing. The next step is bigger datasets, and that seems like a matter of time.
Sources: Ljubicic ML, Madsen A, Juul A, Almstrup K and Johannsen TH (2021). Front. Endocrinol. 12:652888. doi:10.3389/fendo.2021.652888 | Blazhenets G et al. (2019). Journal of Nuclear Medicine, 60(6), 837-843. doi:10.2967/jnumed.118.219097 | Turk M and Pentland A (1991). Eigenfaces for Recognition. Journal of Cognitive Neuroscience, 3(1), 71-86.